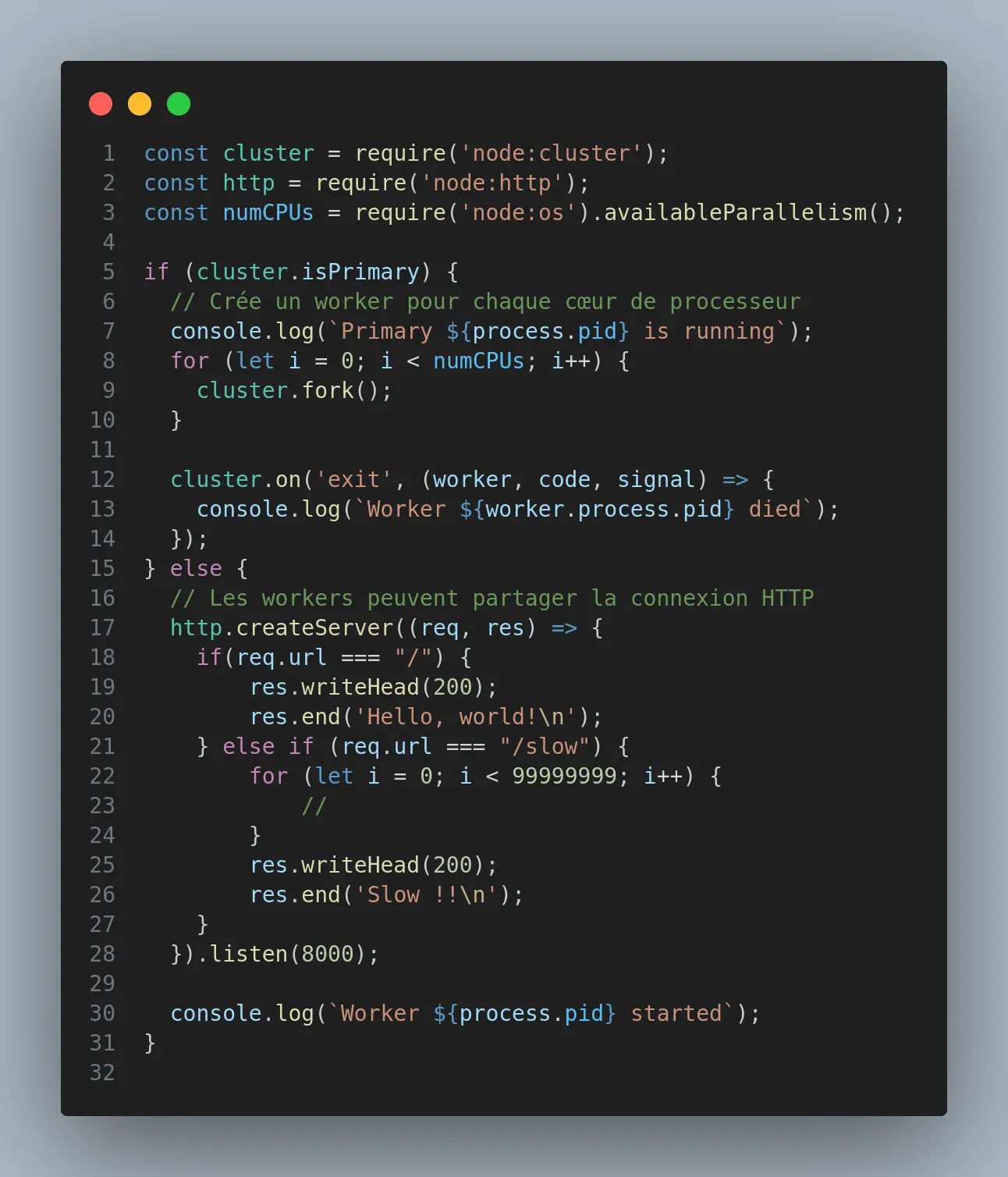
Imagine que ton application Node.js est comme un restaurant. Quand un client arrive, il est servi par un serveur (ton application Node.js). Mais que se passe-t-il si beaucoup de clients arrivent en même temps ? Un seul serveur ne peut pas s'occuper de tout le monde efficacement. C'est là que le clustering entre en jeu !
Le clustering permet de créer plusieurs instances de ton application Node.js (worker) qui partagent le même serveur et écoutent sur le même port. Par défaut, Node.js est monothread, ce qui signifie qu'il n'utilise qu'un seul cœur du processeur. Avec le clustering, vous pouvez créer plusieurs instances de votre application, chacune utilisant un cœur différent.
Dans cet exemple, chaque instance (worker) gère des requêtes indépendamment, ce qui améliore la capacité de traitement de l'application. Si une requête prend un peu plus de temps, cela ne va pas bloquer les autres requêtes, car un autre worker libre pourra les traiter.
Comment ça fonctionne ?
- Le processus principal qui gère tout. Il crée plusieurs workers pour répartir la charge.
- Chaque worker prend des requêtes et les traite indépendamment. Ils sont les clones de ton application.
Cependant, il faut aussi être conscient des défis et des inconvénients associés à la gestion des processus multiples, comme la consommation de mémoire et la gestion des états.